Wussten Sie, dass 80 % der weltweiten Daten aus unstrukturiertem Text bestehen? Dennoch tun sich die meisten Unternehmen schwer damit, aus dieser Informationsschatzgrube verwertbare Erkenntnisse zu gewinnen.
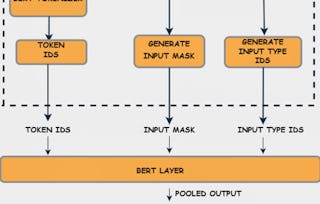
Dieser Kurzkurs wurde entwickelt, um Fachleuten aus den Bereichen maschinelles Lernen und KI dabei zu helfen, durch systematische Modellanpassung und robuste Workflows zur Textvorverarbeitung eine domänenspezifische Verarbeitung natürlicher Sprache zu realisieren. Nach Abschluss dieses Kurses sind Sie in der Lage, BERT-Modelle anhand von Datensätzen mit Spezialisierung fein abzustimmen, automatisierte spaCy-Pipelines zur Textstandardisierung zu erstellen und produktionsreife NLP-Lösungen einzusetzen, die in Ihrem nächsten Projekt messbare Leistungsverbesserungen erzielen. Am Ende dieses Kurses werden Sie in der Lage sein: - Feinabgestimmte Transformer-Sprachmodelle für domänenspezifische Anwendungen zu erstellen - Techniken der Textvorverarbeitung anzuwenden, um eine Pipeline zur Bereinigung und Standardisierung von Rohtext aufzubauen Das Besondere an diesem Kurs ist die Kombination aus praktischer Feinabstimmung mit dem Hugging Face Trainer und dem Aufbau einer Pipeline mit spaCy, wodurch Sie sofort anwendbare Fähigkeiten für reale NLP-Herausforderungen erwerben. Um dieses Projekt erfolgreich zu absolvieren, sollten Sie über Kenntnisse in der Python-Programmierung, grundlegende Konzepte des maschinellen Lernens sowie Vertrautheit mit Transformer-Architekturen verfügen.